シンプルなOCR(Optical Character Recognition:光学文字認識)ソフト。はじめてでも直感的に操作できる。「パパッと読み取りOCR」は、ディスプレイに表示された文字列や紙に印刷された文字列を読み取り、テキスト化できるOCRソフト。例えば、画像文字をテキスト化して、エディタなどで編集できるようにしたり、コピー不可のPDFファイルから文字列を抽出し、テキストファイルに保存したりすることが可能。テキスト化するのに難しい設定などは不要。対象を読み込ませれば、自動的に「読み取り」が開始され、画面に認識結果が表示される。OCRエンジンには、オープンソースの「Tesseract-OCR」を採用している。
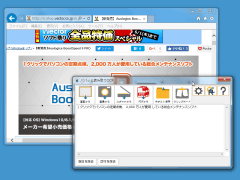
メイン画面は、読み取りモードを選択するためのボタンと、認識結果を出力するためのボタン、「詳細設定」画面を呼び出すためのボタンなどが上部に、中央には認識結果表示エリアが配置された構成。ツールボタンはいずれも大きく、わかりやすい。さらに画面下部には認識結果から「空白を除去」「改行を除去」するためのボタンも用意されている。
選択できる読み取りモードは、
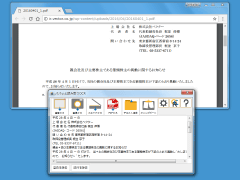
の4種類。「画面から」では、カーソルが十字型に変わり、指定した範囲内の文字列が読み取られる。「画像から」「PDFから」では、ファイル選択ダイアログが表示され、指定したファイルの文字列が読み取られる。「スキャナから」を選択して、パソコンに接続されたスキャナから印刷物の文字列を読み取らせることも可能だ。読み取りが完了すると、画面に認識結果が表示される仕組み。空白・改行を除去できるほか、誤認識された個所をその場で編集することもできる。
誤認識個所を修正し、正しい文字列を取得できたら、「テキスト保存」ボタンでファイルに保存したり、「クリップボード」ボタンでクリップボードに転送したりして、別アプリケーションで再編集すればよい。
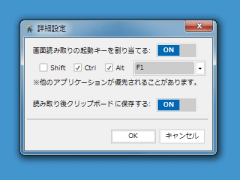
「詳細設定」では、
- 画面読み取りの起動キー(ショートカットキー)を割り当てる
- 読み取り後クリップボードに保存する
のON/OFFを設定できるようになっている。